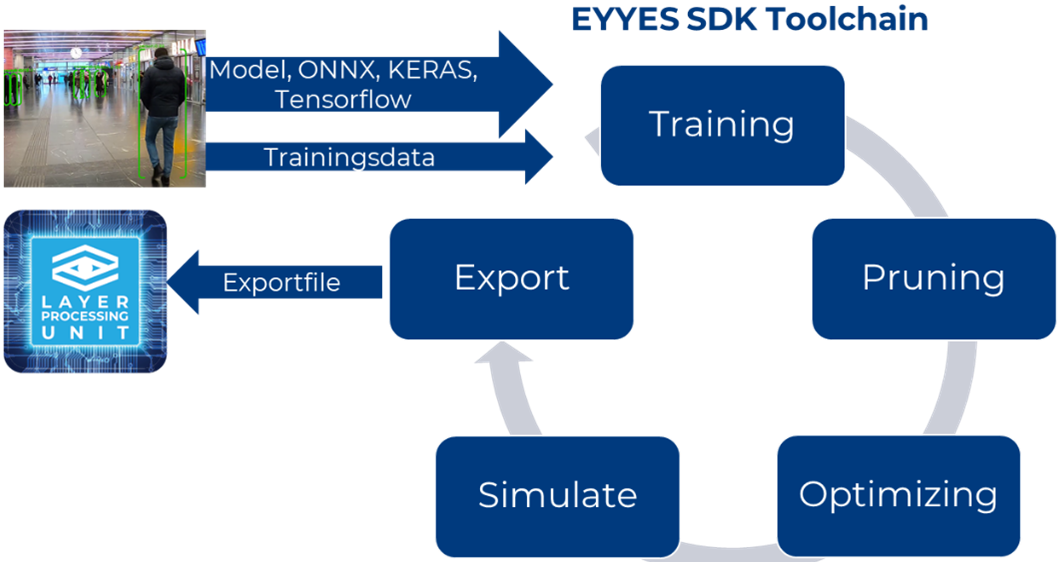
AI Hardware
EYYES Layer Processing Unit
The use of Deep Learning-based systems in mobile applications is growing rapidly, especially for driving and safety-related applications in traffic and industry. The future of artificial intelligence and neural network-based systems is neither CPU nor GPU or TPU, but a completely new AI chip architecture. The solution is called LPU – “Layer Processing Unit” – and represents a paradigm shift in the hardware and software structure of neural networks, which the European technology leader EYYES is already bringing to market in its products.
By multiplying the number of parallel computing operations, the processing speed and data throughput are maximised. This enables the implementation of particularly powerful, energy-efficient systems.

How the new LPU works
First, the neural networks are optimized so that they can be used in an embedded/edge environment. The aim is to reduce the size of the network and the required computing operations without loss of quality.
The second step is to optimize the parallel computing operations in the IP processing core of the LPU. How does this work compared to a GPU and TPU?
[servicebox_sc id=20373]
The comparison with previous technologies
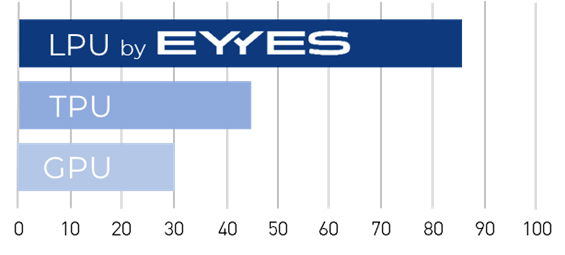
Graphics Processing Unit
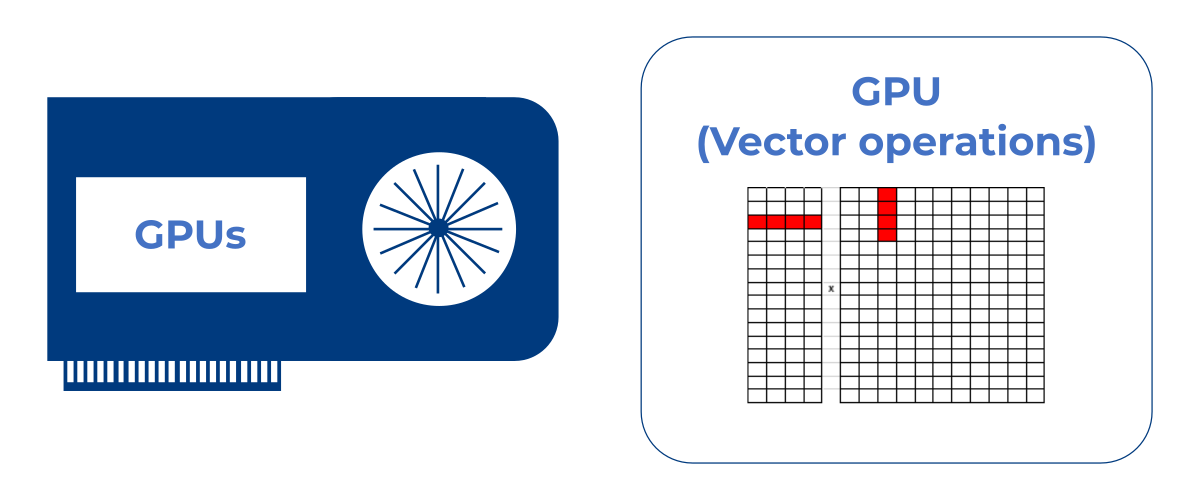
A GPU is very fast and can start many vector operations in parallel, but only process one operation step at a time per computing clock. In order to run through all the individual layers of a neural network, it therefore requires many clocks for computing and buffering – high demands on performance, memory and bandwidth as well as a resulting high energy consumption are the consequence.
Tensor Processing Unit
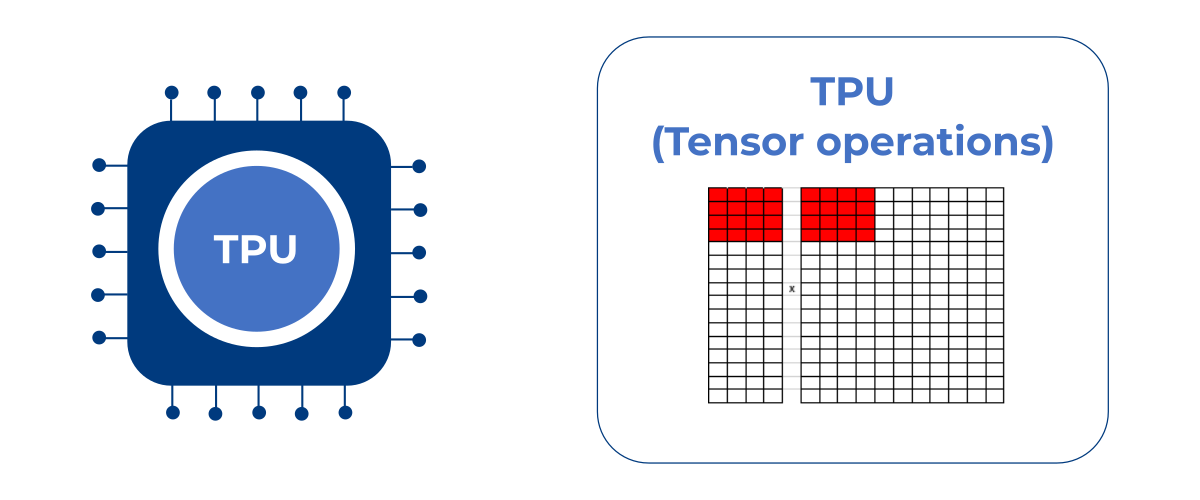
A TPU already works a bit more efficiently in this respect, calculating one tensor with several vectors at a time. Nevertheless, even with a TPU, many clocks are still required for buffering and the final processing of all neurons.
The solution
Die LPU kann in einem einzigen Rechentakt die Tensoren aller Neuronen in einem Layer eines neuronalen Netzes gleichzeitig berechnen, inklusive Addition der Ergebnisse und Berücksichtigung der Aktivierungsfunktion der Neuronen. Sie verarbeitet die eingehenden Daten parallel und führt Aktivierung und Pooling im selben Operationsschritt aus. Durch dieses patentierte Verfahren kann die LPU auch bei geringen Taktfrequenzen die benötigten Milliarden an Rechenoperationen hocheffizient abarbeiten. Sie ist damit eine hocheffiziente Chip- bzw. Prozessortechnologie für Embedded KI-Anwendungen.
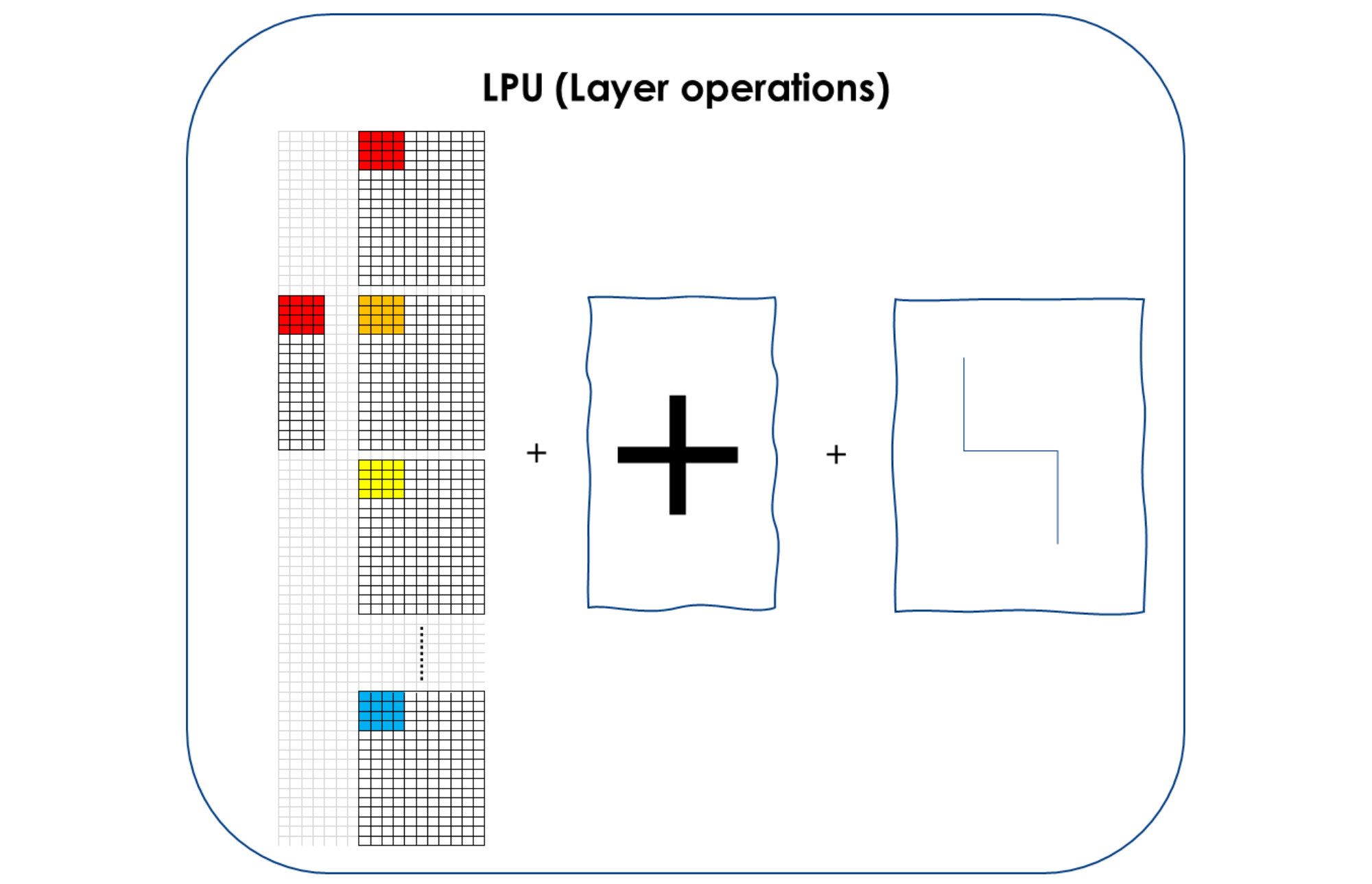

Parallel execution processes are the essential difference to the way graphics and tensor processors work. The performance improvement through these simultaneously running computing operations brings a revolutionary advantage. With comparable implementation in terms of clock frequency and chip technology, the performance is at least 3 times as high as with a GPU and twice as high as with a TPU, as the comparison graphic below impressively shows.
System on Module with integrated LPU
The Real-Time Interface 3.0
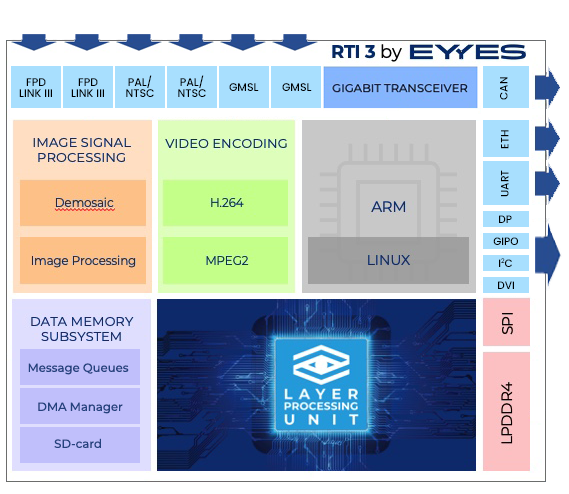
Based on the Layer Processing Unit architecture, EYYES developed the Real Time Interface 3.0 (RTI 3.0). It is a system on module for visually based object recognition that can be used for a wide range of applications. Here, EYYES achieves the enormously high computing power of 18 TOPS on a small board of 67mm by 58mm while fully utilizing the area of the Xilinx Zynq 4 MPSOC FPGAS. Compared to SOMs with conventional TPU processing, the RTI 3 is characterized by low hardware costs, a particularly high energy saving of around 25% and flexible use in a wide range of applications.
The module is capable of processing two independent full HD video streams and outputting them to different interfaces. Its high flexibility also enables customized developments and integration via LINUX drivers, e.g. for autonomous driving assistants.
The custom on the shelf (COTS) functionality of the RTI 3.0 ensures that all basic applications for object detection, i.e. for people and vehicle recognition, are already implemented at delivery. It is thus a leading system for safety-relevant traffic applications that combines the highest performance with the most efficient utilization, leaving previous SOMs far behind in terms of energy efficiency, scalability and deployment flexibility.
Connection overview of the RTI 3.0:

